
Deequ - An Open Source Data Quality Library
unit testing the data...


What is Deequ?
Deequ is a library built on top of Apache Spark for defining "unit tests for data", which measure data quality not only in the small datasets but also at scale for large datasets. It's built on top of Apache Spark and uses Spark's distributed computation engine to define data quality checks. It's a declarative API combining common quality constraints with the user-defined validation code, which enables the "unit tests" for data. Essentially, it's a series of data quality checks that can run within the ETL pipeline - to ensure the data quality is maintained throughout the data pipeline. The tool was developed by Amazon and is now open source.
Dimensions of Data Quality
Deequ defines below dimensions of data quality:
Completeness: The data should not have missing values. It refers to the degree to which an entity includes data required to describe a real-world object.
Consistency: It refers to the degree to which a set of semantic rules are violated by the data.
Intra-relation constraints: These define the range of admissible values for a column in a table, or the allowed combinations of values across columns in a table, or the allowed combinations of values across tables and also specific data types.
Accuracy: Refers to the correctness of data, measured in two ways:
Syntactic: Represents the degree to which the data conforms to the defined schema.
Semantic: Compares the data to the real-world object it represents.
For eg., a column that stores the age of a person should not have a value greater than 100 - is considered as a semantic constraint whereas a column considering a person's age as a string is considered as a syntactic constraint.
Deequ Approach
Deequ platform efficiently executes the resulting constraint validation workload by translating it to aggregation queries on Apache Spark. The platform supports the incremental validation of data quality on growing datasets, and leverages machine learning, e.g., for enhancing constraint suggestions, for estimating the ‘predictability’ of a column, and for detecting anomalies in historic data quality time series. What's more, the platform provides a domain-specific language for defining constraints, and a set of built-in data quality checks. The declarative API allows users to define checks for their datasets - which results in error or warnings during execution. This means we can control the ETL flow to downstream systems based on the data quality checks. This is quite effective because at the time of creating the data pipeline, we can define the data quality checks and the pipeline will fail if the data quality checks fail. And, we never know when the source systems behave over the period of the time. Having these quality checks embedded in the pipeline will help in the data operations in the long run.
How does a constraint look like?
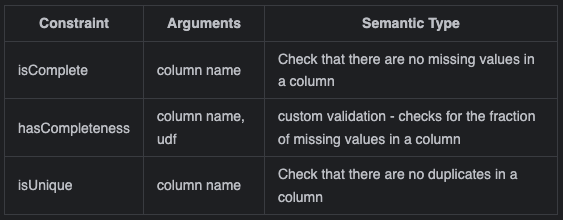
General Syntax

Here you could see how to define the data quality checks in the pipeline and the pipeline will fail if the data quality checks fail. We have used few constraints like isComplete, isUnique, isLessThan, which will produce an error if the data quality check fails. It literally means that the pipeline will fail if any of the constraints fall into this category. Let's see an example.
Deequ Example
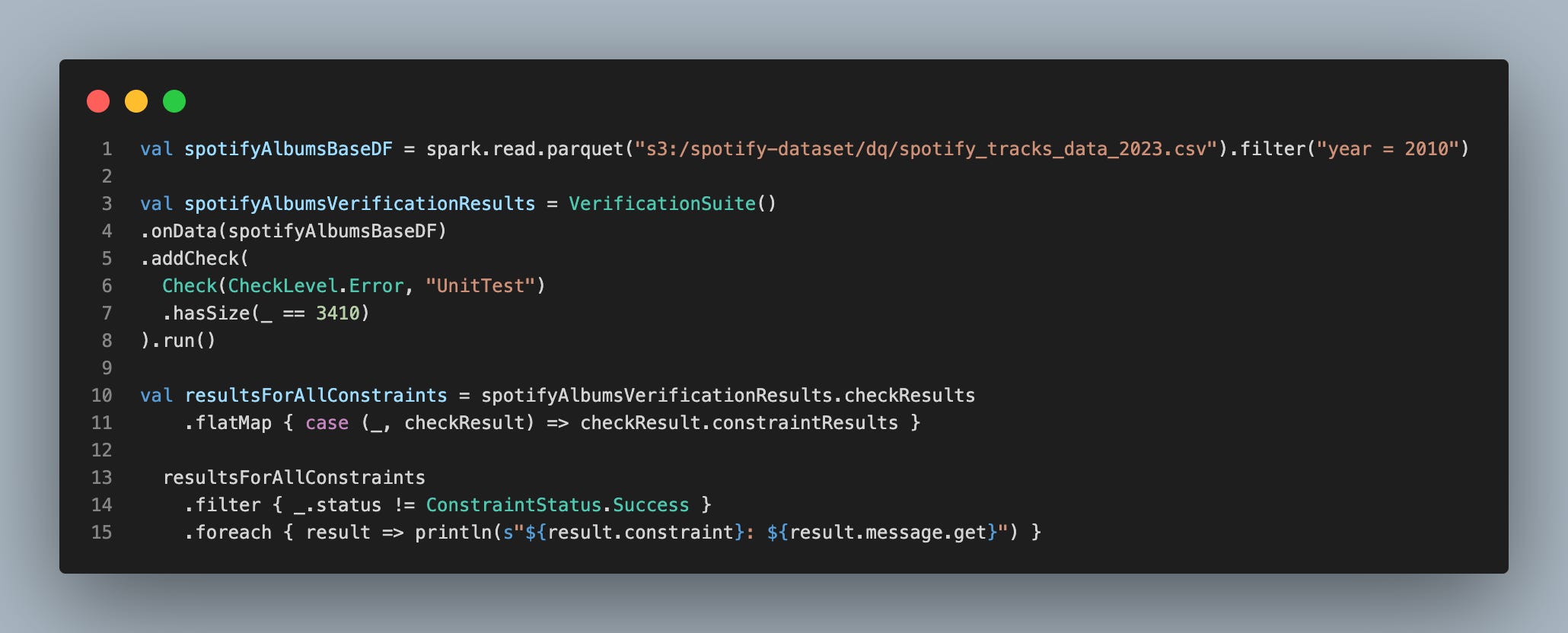
Here in this simple example, we are reading the data from S3 and filtering the data for the year 2010. Then we are defining a constraint to check the size of the data. In this case, we are expecting the size of the data to be 3410, but the actual size of the data is 3409. So, the pipeline will fail with the below error message:
We found errors in the data:
SizeConstraint(Size(None)): Value: 3409 does not meet the constraint requirement!
import com.amazon.deequ.constraints.ConstraintStatusThis is a hypothetical example of setting a constraint on table size unless it's a dimension or a static lookup table, but you could see how the pipeline fails if the data quality check fails.
Constraint Suggestions
If you are not sure about the contents of each column and wanted to evaluate the data quality within the column, there is a way to call the constraint suggestions API, which will give you the suggestions for each column in the dataset.

Here I picked the spotify albums base dataset and used the default Rules to get the constraint suggestions. For each column, it evaluated the data and gave some suggestions on the possible constraints. For eg., for the columns album_id, duration_ms, it is evaluating the data and providing the suggestions:
Constraint suggestion for 'album_id': 'album_id' has less than 1% missing values
The corresponding scala code is .hasCompleteness("album_id", _ >= 0.99, Some("It should be above 0.99!"))
Constraint suggestion for 'duration_ms': 'duration_ms' is not null
The corresponding scala code is .isComplete("duration_ms")We almost are aware that the album_id is a unique key and it should not have any missing values, and it can also list the threshold for the completeness. Similarly, for the duration_ms column, in principle we kind of understand that every album should be of some length and it cannot be null for sure, thats the reality but when it comes to data we receive, there could be anomalies, hence we need to write some quality constraints by looking that the data within each column.
Then, I created a verification result for one of the columns duration_ms similar to the one above:

It then produced the below log message
spotifyAlbumBaseDFVerificationResult: com.amazon.deequ.VerificationResult = VerificationResult(
Success,
Map(
Check(Error, UnitTest, List(CompletenessConstraint(Completeness(duration_ms, None)))) ->
CheckResult(
Check(Error, UnitTest, List(CompletenessConstraint(Completeness(duration_ms, None)))),
Success,
List(
ConstraintResult(
CompletenessConstraint(Completeness(duration_ms, None)),
Success,
None,
Some(DoubleMetric(Column, Completeness, duration_ms, Success(1.0)))
)
)
)
),
Map(Completeness(duration_ms, None) ->
DoubleMetric(Column, Completeness, duration_ms, Success(1.0))
)
)Verification result object contains two maps for separate constraints - Check and Completeness.
Check- checks for errors or issues in the data - like missing values, data type incorrectness or any violations of business rules in particular. It contains the map of error codes and corresopnding error messages.Completeness- checks for the completeness issues in the data - like incomplete rows or missing rows. The Completeness constraint contains a map of duration (in milliseconds) to a DoubleMetric object, which represents the completeness of the data. The DoubleMetric object contains the actual value of the metric and a success indicator. The Completeness constraint has a duration of 1000 milliseconds and a success status. The DoubleMetric object for the Completeness constraint contains the actual value of the metric (1.0) and a success status.
Analyzers and Metrics
Deequ provides a set of analyzers to compute metrics on the data. The Analyzers are used to compute metrics on the data, which can be used to define the constraints unlike the constraint checks, which are used to validate the data. Let's see an examples:

Here we are adding the analyzers of ApproxCountDistinct, Distinctness, Completeness and Compliance as part of the spotifyAnalysis object. Then we are running the analysis on the data and saving the results in the state store. Later, if we wanted to persist this output, we could then convert the results into a dataframe and adding a timestamp column to it. stateStoreCurr and stateStoreNext handle the state information, which are used to store the intermediate results of the analysis - This keeps the state updated when we are trying to run incremental analysis and streaming the data sources.
And, the result looks something like this:

the ApproxCountDistinct analyzer computes the approximate number of distinct values in a column - its fast because it uses the HyperLogLog algorithm to compute the approximate distinct values. This algorithm is also available as part of Data Sketches in Databricks as well, just in case to make use of it.
Versioning
Deequ is available in Maven Central and Spark Packages. One needs to look at the compatibility matrix to find the right version of Deequ for the Spark version.
More details can be found here. If these details are missing or incompatible with the pom.xml or build.sbt, then the build will fail. Similarly, cluster configuration on databricks should be compatible with the spark and scala versions only, while the java version can be different.
Anomaly detection
Anomaly Detection Algorithms: Deequ uses standard algorithms for anomaly detection, such as the OnlineNormal algorithm, which computes a running mean and variance estimate and compares the series values to a user-defined bound on the number of standard deviations they are allowed to be different from the mean.
Differencing: Deequ allows users/developers to specify the degree of differencing applied prior to running the anomaly detection, which helps stationarize the time series to be analyzed.
User-defined Thresholds: Deequ gives provision to users to set their own thresholds for anomaly detection, enabling them to customize the detection process according to their specific needs and requirements.
Pluggable Anomaly Detection and Time Series Prediction: Deequ also allows users to plug in their own algorithms for anomaly detection and time series prediction, providing flexibility and customization for organizations with specific use cases and data patterns. Generally the data patterns are not stationary and they change over the period of time for a particular reason/behavior, so it's really important to have control on the threshold boundaries to be setup by the user/developer. Lets see an example:

Here we are creating a new dataframe with the updated population data and then we are running the verification suite on the updated dataframe. Here we are enforcing the anomaly on the size of the dataframe, which is the number of rows in the dataframe, which cannot be more than 2 times the previous run dataframe size.
And, the result looks something like this:

Incremental computation
Quite often in the data platforms, we need to always load latest or new data (as a batch or a stream) into the data lake.
This means the metrics calculated are always changing and we need to keep track of the metrics over the period of time.
This is implemented using the State Store.
Once the computation of metrics is done, the results are then stored in the state store and in the next subsequent runs, the metrics results are computed considering the previously stored state information and the incremental data.

Similarly, the partitions are also handled in the similar manner to compute the metrics on the changed partitions only, provided the state store is maintained on the partition level.
Deequ Implementation
This library is written on top of Apache Spark, it uses the distributed computation engine to compute the metrics on the spark dataframe. Initially it was developed in Scala but now it supports Pyspark as well.
The entry point for Deequ is a spark dataframe. The user-facing API consists of constraints and checks, allows users to declaratively define the particular statistics and the particular verification code to be run.
When checks are executed, Deequ identifies the Metrics required to compute. Each Metric is there is a corresponding Analyzer, which are capable of computing the particular metrics.
The selected Analyzers are given to a AnalysisRunner - which applies simple set of optimizations for the computation of the metrics. For eg., in the spotify dataset, all the metrics like size, completeness, distinctness, compliance, etc., are handled by the AnalysisRunner and is a single pass computation over the SparkSQL query.
The resulting metrics are stored in DynamoDB. The incremental computation state-store information is stored in the S3 filesystem.
For predictive estimations, it uses the user given column names are featurized by concatenating their string representation.
The result is tokenized and hashed using Spark's Tokenizer and HashingTF. The trained classification model is applied to predict values on a held-out fraction of the data. It uses Naive-Bayes classifier to predict the values.
Pydeequ
Pydeequ is a python wrapper for Deequ, which is built on top of PySpark. We can simply install pip install pydeequ and start using it. We can get more information about the pydeequ here.
Limitations
Deequ is a data quality library. It's not a tool like Informatica Data Quality or Talend Data Quality, which can connect to multiple data sources, have a dedicated UI for business users to define the data quality rules and generate reports
It should be considered, indeed more of a data quality library than a standalone data quality tool. Deequ, on the other hand, is more developer-centric and integrates with Spark for scalable and distributed data processing.
Deequ also does not have a UI, which means it's not a tool for business users. It is meant majorly for developers and data engineers.
The data source needs to be brought in as a spark dataframe and then only the data quality checks can be applied - This means that all the sources supported by the Spark.
Although it is designed for Spark, it can still be used to perform dq checks on data stored in snowflake - provided the data needs to be accessed via spark dataframe. Having said that, compatibility needs to be checked between the spark, snowflake and java 11 versions.
Moreover, the community support for Deequ is not as good as other data centric open source projects like Apache Spark, Flink, Kafka, etc., - which is a bit of a concern in terms of adopting this tool for the organizations
Lastly, its a laborious task to define the data quality checks for each column in the dataset, which is a bit of a challenge for the developers - most often developers do not have full domain understanding to setup the rules for every column in the dataset. This is more of a common issue in terms of data quality checks, but deequ is not an exception, but what's interesting is that the metrics can be stored into a database and can be tracked over the period of time, which is a great feature to have.
Industry Adoption
Because its an open source project, big companies find it relatively easy to consider this tool for handling DQ into their data platform ingestion processes. For eg.,
Deequ is used by Amazon for their internal data quality checks of many large datasets.
Big consultancy firm like Thoughtworks has used for one of their clients.
Netflix has been heavily using Deequ and GreatExpectations for data quality checks in their data platform.
And, several other big companies tried and tested this tool for their data quality checks.
Alternatives
GreatExpectations
Soda
Pandera
whylogs
spark-expectations
Conclusion
If the ETL pipelines are built on top of Spark, then Deequ comes in place as a handy tool to define the data quality checks, which gets embedded in the pipeline.
It's declarative API style makes it easy to define the data quality checks and the pipeline will fail if the data quality checks fail.
It's a great engineering project, leveraging Spark's distributed computation engine to pass the data quality checks/constraints in an optimized SparkSQL query. The query execution engines are generally faster in terms of implementation.
It also provides a number of missing values in a continuously produced dataset, which could be changing in the trends or behavioral patterns - which is often a most sought out feature requested by business analysts
This library provides the data profiling capabilities like summary statistics on each column level. It can be used to profile the data and generate the data quality reports - gives recommendations for every column in the dataset - based on the machine learning model trained on the large datasets. This gives some sort of certainty on the data quality checks defined.
Despite some of the limitations, it still serves as a good data quality library for Spark and PySpark users. It's a great tool to have in the data platforms.
References
Community
This article is written by Chanukya Pekala for an open source community called DataTribe Collective
There will be an update to the article providing the github code details like a project. Stay Tuned. :)